-
看看

-
性别男,爱好女可还行






搜索到
156
篇与
罗小黑
的结果
-
 Redhat8.0本地Yum源配置方法 由于redhat系统的yum源需要注册后再使用(也就是要花钱买),我们可以自己创建一个yum的源来解决。问题提示:system is not registered with an entitlement server. You can use subscription-manager to register1、挂载系统光盘到/mnt/cdrom目录mkdir -p /mnt/cdrom mount /dev/sr0 /mnt/cdrom2、设置系统启动后自动挂载/mnt/cdrom# blkid #查看文件类型就是下面的iso9660 echo "/dev/sr0 /mnt/cdrom iso9660 defaults 0 0" >>/etc/fstab3、创建RHEL8.repovi /etc/yum.repos.d/RHEL8.repo [BaseOS] name=BaseOS baseurl=file:///mnt/cdrom/BaseOS enabled=1 gpgcheck=0 [AppStream] name=AppStream baseurl=file:///mnt/cdrom/AppStream enabled=1 gpgcheck=04、测试yum配置是否可用 yum install -y lrzsz 或者dnf -y install lrzszPS:dnf是新一代的rpm包管理器,取代了Yum包管理器,但是原来的yum命令依旧可以用
Redhat8.0本地Yum源配置方法 由于redhat系统的yum源需要注册后再使用(也就是要花钱买),我们可以自己创建一个yum的源来解决。问题提示:system is not registered with an entitlement server. You can use subscription-manager to register1、挂载系统光盘到/mnt/cdrom目录mkdir -p /mnt/cdrom mount /dev/sr0 /mnt/cdrom2、设置系统启动后自动挂载/mnt/cdrom# blkid #查看文件类型就是下面的iso9660 echo "/dev/sr0 /mnt/cdrom iso9660 defaults 0 0" >>/etc/fstab3、创建RHEL8.repovi /etc/yum.repos.d/RHEL8.repo [BaseOS] name=BaseOS baseurl=file:///mnt/cdrom/BaseOS enabled=1 gpgcheck=0 [AppStream] name=AppStream baseurl=file:///mnt/cdrom/AppStream enabled=1 gpgcheck=04、测试yum配置是否可用 yum install -y lrzsz 或者dnf -y install lrzszPS:dnf是新一代的rpm包管理器,取代了Yum包管理器,但是原来的yum命令依旧可以用 -
『教程』首页及文章页滚动广告栏 前言因为之前在很多网站上都能看到广告,虽然但是,这对很多博主来说也是一笔额外的收入,我一直是入不敷出!:@(吐血倒地) 然后我看到了执念博客的首页广告栏,虽然曝光确实大,但是用户体验极其不好,因为要翻很多广告才能翻到文章,就像这样:所以我就想到了滚动广告,一个广告的位置,能够显示多条广告成果展示{tabs}{tabs-pane label="首页"}{/tabs-pane}{tabs-pane label="文章页"}{/tabs-pane}{/tabs}教程开始灵感及相关代码来自于Joe主题的首页轮播图一、添加后台打开 functions.php 添加以下代码$JADPost = new Typecho_Widget_Helper_Form_Element_Textarea( 'JADPost', NULL, NULL, '文章页顶部广告', '介绍:用于设置文章页顶部广告 <br /> 格式:广告图片 || 跳转链接 (中间使用两个竖杠分隔)<br /> 注意:如果您只想显示图片不想跳转,可填写:广告图片 || javascript:void(0) <br /> 其他:一行一个,一行代表一个轮播广告图' ); $JADPost->setAttribute('class', 'joe_content joe_post'); $form->addInput($JADPost);这是文章页的代码,因为首页广告主题自带了二、添加滚动广告栏{tabs}{tabs-pane label="首页"} 因为首页已经有广告位了,所以直接替换就行了将主题 index.php 的以下代码直接替换为新代码{collapse}{collapse-item label="代码位置" open}{/collapse-item}{collapse-item label="新代码"}隐藏内容,请前往内页查看详情{/collapse-item}{/collapse}{/tabs-pane}{tabs-pane label="文章页"}文章页直接在主题的 post.php 文件内合适的地方加入以下代码{collapse}{collapse-item label="代码位置" open}{/collapse-item}{collapse-item label="代码"}隐藏内容,请前往内页查看详情{/collapse-item}{/collapse}{/tabs-pane}{/tabs}三、修改广告栏样式{tabs}{tabs-pane label="首页"} 直接在 Joe/assets/css 打开 joe.index.min.css 然后在最后添加以下代码.joe_index__ad .swiper-container{height: 180px!important;border-radius: var(--radius-inner);}.joe_index__ad .swiper-container .icon{position:absolute;z-index:1;top:10px;right:10px;font-size:12px;background:rgba(0,0,0,0.25);padding:2px 5px;border-radius:2px;color:#ebebeb;pointer-events:none}@media (max-width: 768px){.joe_index__ad .swiper-container{height: 120px!important}.joe_index__ad .swiper-container .image{height: 120px;object-fit: cover;border-radius: var(--radius-inner);}}{/tabs-pane}{tabs-pane label="文章页"}直接在 Joe/assets/css 打开 joe.post.min.css 然后在最后添加以下代码.joe_post__ad .swiper-container{height: 180px!important;margin-top:15px;border-radius: var(--radius-inner);}.joe_post__ad .swiper-container .icon{position:absolute;z-index:1;top:10px;right:10px;font-size:12px;background:rgba(0,0,0,0.25);padding:2px 5px;border-radius:2px;color:#ebebeb;pointer-events:none}@media (max-width: 768px){.joe_post__ad .swiper-container{height: 120px!important}.joe_post__ad .swiper-container .image{height: 120px;object-fit: cover;border-radius: var(--radius-inner);}}{/tabs-pane}{/tabs}四、添加滚动效果{tabs}{tabs-pane label="首页"}首页因为引入了滚动效果,所有不需要设置,会直接调用首页轮播图的滚动效果但是会根据首页轮播图的滚动方式滚动,效果不太好,暂时没想到比较好的解决方法{/tabs-pane}{tabs-pane label="文章页"}首先在主题的 post.php 文件内 标签内加入以下代码<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/swiper@5.4.5/css/swiper.min.css" /> <script src="https://cdn.jsdelivr.net/npm/swiper@5.4.5/js/swiper.min.js"></script>然后再在 Joe/assets/js 打开 joe.post_page.min.js 然后在最后添加以下代码if(0!==$(".joe_post__ad .swiper-container").length){let e="vertical";new Swiper(".swiper-container",{keyboard:!1,direction:e,loop:!0,autoplay:!0,mousewheel:!0,pagination:{el:".swiper-pagination"},})}添加位置{/tabs-pane}{/tabs}教程结束大功告成,快刷新你的网站看看效果吧!
-
Ubuntu20.04安装MySQL5.7.18、jdk1.8、tomcat8.0.47 安装Mysql5.7.18数据库。在官网下载:https://dev.mysql.com/downloads/mysql/也可以选择用我的修改后的:使用deb包进行安装将下载好的mysql-server_5.7.18压缩包导入linux服务器,然后进行下面的操作。新建目录 mkdir mysql5.7.18 mv mysql-server_5.7.18-1ubuntu18.04_amd64.deb-bundle.tar ./mysql5.7.18 # 解压 cd mysql5.7.18 sudo tar -xf mysql-server_5.7.18-1ubuntu18.04_amd64.deb-bundle.tar # 解压出来的deb安装包如下: root@ubuntu:/home/ubuntu# ls -l mysql/ total 191696 -rw-r--r-- 1 root root 232656 Feb 26 2020 libmecab2_0.996-10build1_amd64.deb -rw-r--r-- 1 7155 31415 839204 Mar 18 2017 libmysqlclient20_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 7155 31415 1184016 Mar 18 2017 libmysqlclient-dev_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 7155 31415 16790008 Mar 18 2017 libmysqld-dev_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 root root 83048 Feb 26 2020 libtinfo5_6.2-0ubuntu2_amd64.deb -rw-r--r-- 1 7155 31415 12630 Mar 18 2017 mysql-client_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 7155 31415 78622 Mar 18 2017 mysql-common_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 7155 31415 8213206 Mar 18 2017 mysql-community-client_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 7155 31415 26429638 Mar 18 2017 mysql-community-server_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 7155 31415 142392244 Mar 18 2017 mysql-community-source_5.7.18-1ubuntu16.10_amd64.deb -rw-r--r-- 1 7155 31415 12626 Mar 18 2017 mysql-server_5.7.18-1ubuntu16.10_amd64.deb PS:如过是你自己在官网下载的安装包里面是没有libtinfo5、libmecab2这两个的,需要你自己下载 # 删除2个测试相关的包 sudo rm -f mysql-testsuite_5.7.18-1ubuntu16.10_amd64.deb sudo rm -f mysql-community-test_5.7.18-1ubuntu16.10_amd64.deb #在线安装依赖 root@ubuntu:/home/ubuntu/mysql# sudo apt-get install libmecab2 root@ubuntu:/home/ubuntu/mysql# sudo apt-get install libmecab2 #离线安装 sudo dpkg -i libtinfo5_6.2-0ubuntu2_amd64.deb sudo dpkg -i libmecab2_0.996-10build1_amd64.deb 这些安装包的顺序我忘记了,你可以自己尝试一下,也可以直接用下面命令一起安装 # 用dpkg进行安装 sudo dpkg -i mysql-*.deb之后它会弹出一个窗口提示你设置root密码安装完成后查看mysql版本和服务mysql -V # 查看mysql版本 netstat -tap | grep mysql # 查看mysql服务安装JDK{cloud title="点击下载" type="wy" url="https://share.weiyun.com/5p7MsV6c" password=""/}2、创建目录执行如下命令,在 /usr/ 目录下创建 java 目录。mkdir /usr/java cd /usr/java 将下载的文件 jdk-8u151-linux-x64.tar.gz 复制到 /usr/java/ 目录下。3、解压 JDK执行如下命令,解压文件。tar -zxvf jdk-8u151-linux-x64.tar.gz 4、设置环境变量编辑 /etc/profile 文件,在 profile 文件中添加如下内容并保存:set java environment JAVA_HOME=/usr/java/jdk1.8.0_28 JRE_HOME=/usr/java/jdk1.8.0_281/jre CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JRE_HOME CLASS_PATH PATH 其中 JAVA_HOME,JRE_HOME 请根据自己的实际安装路径及 JDK 版本配置。使之修改生效,执行如下:source /etc/profile 5、测试执行如下命令进行测试。java -version 若显示 Java 版本信息,则说明 JDK 安装成功: java version "1.8.0_151" Java(TM) SE Runtime Environment (build 1.8.0_151-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)安装tomcat下载:https://archive.apache.org/dist/tomcat/执行如下命令,在 /usr/ 目录下创建 tomcat 目录。mkdir /usr/tomcat cd /usr/tomcat把下载好的解压到tomcat目录root@ubuntu:/home/ubuntu# ls -l /usr/tomcat/ total 112 drwxr-xr-x 2 root root 4096 Sep 30 06:00 bin drwxr-xr-x 3 root root 4096 Sep 30 05:56 conf drwxr-xr-x 2 root root 4096 Sep 30 05:50 lib -rw-r--r-- 1 root root 57011 Sep 29 2017 LICENSE drwxr-xr-x 2 root root 4096 Oct 7 12:02 logs -rw-r--r-- 1 root root 1444 Sep 29 2017 NOTICE -rw-r--r-- 1 root root 6741 Sep 29 2017 RELEASE-NOTES -rw-r--r-- 1 root root 16195 Sep 29 2017 RUNNING.txt drwxr-xr-x 2 root root 4096 Sep 30 05:50 temp drwxr-xr-x 7 root root 4096 Sep 29 2017 webapps drwxr-xr-x 3 root root 4096 Sep 30 05:56 work root@ubuntu:/home/ubuntu# 进入bin目录修改shutdown.sh和startup.sh文件,在最后添加一下内容(两个文件一样)#set java environment export JAVA_HOME=/usr/java #jdk的存放地址 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH #tomcat export TOMCAT=/usr/tomcat #tomcat的存放地址到这里Tomcat服务就安装以及配置完成了,接下来可以开启Tomcat服务,检验一下是否成功,使用命令开启服务: ./startup.shTomcat服务在Ubuntu 21.04开机自启动1、进入tomcat下的bin目录/usr/tomcat/bin2、复制catalina.sh到/etc/init.d目录下cp ./catalina.sh /etc/init.d3、重命名cd /etc/init.d mv ./catalina.sh tomcat配置环境变量vim /etc/init.d/tomcat 在文件开始位置加入以下内容:CATALINA_HOME=/usr/tomcat JAVA_HOME=/usr/java添加到开机自动服务:update-rc.d –f tomcat defaults 用如下命令查看是否设置成功:sysv-rc-conf --list tomcatPS:如果提示你没有这个命令,进行以下操作编辑sources.list文件sudo vi /etc/apt/sources.list软件源sources.list文件中添加如下一列文本deb http://archive.ubuntu.com/ubuntu/ trusty main universe restricted multiverse之后 apt update 安装 apt-get install sysv-rc-conf输入sysv-rc-conf 找到tomcat服务,将2,3,4,5级别选中,即可实现开机自动启动。
-
解决Ubuntu系统无法连接网络 今天在公司安装了Ubuntu系统,安装之后发现不能上网,在网上了找了好多解决方法,都没找到,主要是我对Ubuntu系统不是很熟 :@(阴暗) ,而且网上大部都是Ubuntu20以前的解决方法,20版后network配置文件变了。在Ubuntu20.04版本中使用netplan管理网络在安装好的Ubuntu20.04中没有networking和NetworkManage服务netplan配置文件:/etc/netplan/*.yaml,文件名每一个都不一样netplan示例文件:/usr/share/doc/netplan/example目录下,在该目录下有各种示例文件,可以提供帮助修改网卡配置文件vim /etc/netplan/00-installer-config.yaml network: ethernets : ens32 : addresses : - 192.168.0.138/24 gateway4 : 192.168.0.1 nameservers : addresses : - 8.8.8.8 version : 2netplan apply具体可看:https://netplan.io/examples
-
-
Redis集群搭建 主从复制概述主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave已读为主默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。主从复制的作用主从复制的作用主要包括:数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。环境配置只配置从库,不用配置主库127.0.0.1:6379> info replication # Replication role:master connected_slaves:0 master_replid:f47467f195c4ed51c50938a60c17de4b01bb0f72 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0复制3个配置文件,然后修改对应的信息1、端口2、pid名字3、log文件名字4、 dump.rdp名字一主二从 从机127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 #slaveof host 6379 OK 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_repl_offset:42 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:da314952dadd611849cb227b8706af7bcd8af486 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:42 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:42 127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 #slaveof host 6379 OK 127.0.0.1:6381> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:8 master_sync_in_progress:0 slave_repl_offset:224 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:da314952dadd611849cb227b8706af7bcd8af486 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:224 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:113 repl_backlog_histlen:112建议在配置文件中设置,用命令的话是暂时的主机可写,从机可读如果主机断开连接,从机依旧可以连接到主机,但是没有写的权限,一旦主机恢复,从机就可以再次读取主机信息。如果是用命令行配置的从机,一旦断开连接就会变成主机,需要重新配置,但是在配置文件配置的就不会出现这种情况主从复制(复制原理)Slave启动成功连接到master后会发送一个sync同步命令Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后, master将传送整个数据文件到slave , 并完成一-次完全同步。全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。增量复制: Master继续将新的所有收集到的修改命令依次传给slave ,完成同步但是只要是重新连接master , 一次完全同步(全量复制)将被自动执行层层链路上一个M链接下一个S这个时候如果主机(79)宕机,我们可以用SLAVEOF no one80从机就会变成主机,如果79主机恢复,需要从新配置哨兵模式主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预 ,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供 了Sentinel (哨兵)架构来解决这个问题。谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库.哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一一个独立的进程 ,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。这里的哨兵有两个作用通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。当哨兵监测到master宕机,会自动将slave切换成master ,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票 ,投票的结果由一个哨兵发起,进行failover[故障转移]操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。测试配置哨兵配置文件vim sentinel.conf# 监听端口 port 26379 # 后台运行 daemonize yes #pid文件 pidfile /var/run/redis-sentinel.pid # 哨兵得日志文件 logfile "sentinel.log" # 日志文件存放路径 dir /www/server/redis/ # 设置初始master以及法定认为下线人数: #sentinel monitor <master-name> <ip> <redis-port> <quorum> sentinel monitor mymaster 192.168.0.10 6379 1 # master主观下线时间,默认30秒,30秒内没有回复pong,则认为下线了 #sentinel down-after-milliseconds <master-name> <milliseconds> sentinel down-after-milliseconds mymaster 30000 # 指定故障转移超时时间,默认为3分钟 sentinel failover-timeout mymaster 180000 # 设置通知脚本,发生故障转移可以向管理员发送通知(可选) sentinel notification-script mymaster /www/server/redis/notify.sh # 禁止修改脚本,避免脚本重置 sentinel deny-scripts-reconfig yes启动哨兵模式[root@cs bin]# redis-sentinel xhconfig/sentinel.conf 如果master节点断开了,这个时候就会从从机随机选一个从机当主机如果主机回来了,只能归并到新的主机下,当作从机优点:1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有2、主从可以切换,故障可以转移,系统的可用性就会更好3、哨兵模式就是主从模式的升级,手动到自动,更加健壮!缺点:1、Redis 不好啊在线扩容的,集群容量一旦到达上限,在线扩容就十分麻烦!2、实现哨兵模式的配置其实是很麻烦的,里面有很多选择!哨兵全部配置[root@cs bin]# cat /opt/redis-5.0.13/sentinel.conf # Example sentinel.conf # *** IMPORTANT *** # # By default Sentinel will not be reachable from interfaces different than # localhost, either use the 'bind' directive to bind to a list of network # interfaces, or disable protected mode with "protected-mode no" by # adding it to this configuration file. # # Before doing that MAKE SURE the instance is protected from the outside # world via firewalling or other means. # # For example you may use one of the following: # # bind 127.0.0.1 192.168.1.1 # # protected-mode no # port <sentinel-port> # The port that this sentinel instance will run on port 26379 # By default Redis Sentinel does not run as a daemon. Use 'yes' if you need it. # Note that Redis will write a pid file in /var/run/redis-sentinel.pid when # daemonized. daemonize no # When running daemonized, Redis Sentinel writes a pid file in # /var/run/redis-sentinel.pid by default. You can specify a custom pid file # location here. pidfile /var/run/redis-sentinel.pid # Specify the log file name. Also the empty string can be used to force # Sentinel to log on the standard output. Note that if you use standard # output for logging but daemonize, logs will be sent to /dev/null logfile "" # sentinel announce-ip <ip> # sentinel announce-port <port> # # The above two configuration directives are useful in environments where, # because of NAT, Sentinel is reachable from outside via a non-local address. # # When announce-ip is provided, the Sentinel will claim the specified IP address # in HELLO messages used to gossip its presence, instead of auto-detecting the # local address as it usually does. # # Similarly when announce-port is provided and is valid and non-zero, Sentinel # will announce the specified TCP port. # # The two options don't need to be used together, if only announce-ip is # provided, the Sentinel will announce the specified IP and the server port # as specified by the "port" option. If only announce-port is provided, the # Sentinel will announce the auto-detected local IP and the specified port. # # Example: # # sentinel announce-ip 1.2.3.4 # dir <working-directory> # Every long running process should have a well-defined working directory. # For Redis Sentinel to chdir to /tmp at startup is the simplest thing # for the process to don't interfere with administrative tasks such as # unmounting filesystems. dir /tmp # sentinel monitor <master-name> <ip> <redis-port> <quorum> # # Tells Sentinel to monitor this master, and to consider it in O_DOWN # (Objectively Down) state only if at least <quorum> sentinels agree. # # Note that whatever is the ODOWN quorum, a Sentinel will require to # be elected by the majority of the known Sentinels in order to # start a failover, so no failover can be performed in minority. # # Replicas are auto-discovered, so you don't need to specify replicas in # any way. Sentinel itself will rewrite this configuration file adding # the replicas using additional configuration options. # Also note that the configuration file is rewritten when a # replica is promoted to master. # # Note: master name should not include special characters or spaces. # The valid charset is A-z 0-9 and the three characters ".-_". sentinel monitor mymaster 127.0.0.1 6379 2 # sentinel auth-pass <master-name> <password> # # Set the password to use to authenticate with the master and replicas. # Useful if there is a password set in the Redis instances to monitor. # # Note that the master password is also used for replicas, so it is not # possible to set a different password in masters and replicas instances # if you want to be able to monitor these instances with Sentinel. # # However you can have Redis instances without the authentication enabled # mixed with Redis instances requiring the authentication (as long as the # password set is the same for all the instances requiring the password) as # the AUTH command will have no effect in Redis instances with authentication # switched off. # # Example: # # sentinel auth-pass mymaster MySUPER--secret-0123passw0rd # sentinel down-after-milliseconds <master-name> <milliseconds> # # Number of milliseconds the master (or any attached replica or sentinel) should # be unreachable (as in, not acceptable reply to PING, continuously, for the # specified period) in order to consider it in S_DOWN state (Subjectively # Down). # # Default is 30 seconds. sentinel down-after-milliseconds mymaster 30000 # sentinel parallel-syncs <master-name> <numreplicas> # # How many replicas we can reconfigure to point to the new replica simultaneously # during the failover. Use a low number if you use the replicas to serve query # to avoid that all the replicas will be unreachable at about the same # time while performing the synchronization with the master. sentinel parallel-syncs mymaster 1 # sentinel failover-timeout <master-name> <milliseconds> # # Specifies the failover timeout in milliseconds. It is used in many ways: # # - The time needed to re-start a failover after a previous failover was # already tried against the same master by a given Sentinel, is two # times the failover timeout. # # - The time needed for a replica replicating to a wrong master according # to a Sentinel current configuration, to be forced to replicate # with the right master, is exactly the failover timeout (counting since # the moment a Sentinel detected the misconfiguration). # # - The time needed to cancel a failover that is already in progress but # did not produced any configuration change (SLAVEOF NO ONE yet not # acknowledged by the promoted replica). # # - The maximum time a failover in progress waits for all the replicas to be # reconfigured as replicas of the new master. However even after this time # the replicas will be reconfigured by the Sentinels anyway, but not with # the exact parallel-syncs progression as specified. # # Default is 3 minutes. sentinel failover-timeout mymaster 180000 # SCRIPTS EXECUTION # # sentinel notification-script and sentinel reconfig-script are used in order # to configure scripts that are called to notify the system administrator # or to reconfigure clients after a failover. The scripts are executed # with the following rules for error handling: # # If script exits with "1" the execution is retried later (up to a maximum # number of times currently set to 10). # # If script exits with "2" (or an higher value) the script execution is # not retried. # # If script terminates because it receives a signal the behavior is the same # as exit code 1. # # A script has a maximum running time of 60 seconds. After this limit is # reached the script is terminated with a SIGKILL and the execution retried. # NOTIFICATION SCRIPT # # sentinel notification-script <master-name> <script-path> # # Call the specified notification script for any sentinel event that is # generated in the WARNING level (for instance -sdown, -odown, and so forth). # This script should notify the system administrator via email, SMS, or any # other messaging system, that there is something wrong with the monitored # Redis systems. # # The script is called with just two arguments: the first is the event type # and the second the event description. # # The script must exist and be executable in order for sentinel to start if # this option is provided. # # Example: # # sentinel notification-script mymaster /var/redis/notify.sh # CLIENTS RECONFIGURATION SCRIPT # # sentinel client-reconfig-script <master-name> <script-path> # # When the master changed because of a failover a script can be called in # order to perform application-specific tasks to notify the clients that the # configuration has changed and the master is at a different address. # # The following arguments are passed to the script: # # <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port> # # <state> is currently always "failover" # <role> is either "leader" or "observer" # # The arguments from-ip, from-port, to-ip, to-port are used to communicate # the old address of the master and the new address of the elected replica # (now a master). # # This script should be resistant to multiple invocations. # # Example: # # sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # SECURITY # # By default SENTINEL SET will not be able to change the notification-script # and client-reconfig-script at runtime. This avoids a trivial security issue # where clients can set the script to anything and trigger a failover in order # to get the program executed. sentinel deny-scripts-reconfig yes # REDIS COMMANDS RENAMING # # Sometimes the Redis server has certain commands, that are needed for Sentinel # to work correctly, renamed to unguessable strings. This is often the case # of CONFIG and SLAVEOF in the context of providers that provide Redis as # a service, and don't want the customers to reconfigure the instances outside # of the administration console. # # In such case it is possible to tell Sentinel to use different command names # instead of the normal ones. For example if the master "mymaster", and the # associated replicas, have "CONFIG" all renamed to "GUESSME", I could use: # # SENTINEL rename-command mymaster CONFIG GUESSME # # After such configuration is set, every time Sentinel would use CONFIG it will # use GUESSME instead. Note that there is no actual need to respect the command # case, so writing "config guessme" is the same in the example above. # # SENTINEL SET can also be used in order to perform this configuration at runtime. # # In order to set a command back to its original name (undo the renaming), it # is possible to just rename a command to itsef: # # SENTINEL rename-command mymaster CONFIG CONFIG
-
Redis持久化 Redis持久化 redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一但服务器进程退出,服务器中的数据库状态也会消失,所有redis提供了持久化功能redis 提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。 RDB,简而言之,就是在不同的时间点,将 redis 存储的数据生成快照并存储到磁盘等介质上; AOF,则是换了一个角度来实现持久化,那就是将 redis 执行过的所有写指令记录下来,在下次 redis 重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。 其实 RDB 和 AOF 两种方式也可以同时使用,在这种情况下,如果 redis 重启的话,则会优先采用 AOF 方式来进行数据恢复,这是因为 AOF 方式的数据恢复完整度更高。 如果你没有数据持久化的需求,也完全可以关闭 RDB 和 AOF 方式,这样的话,redis 将变成一个纯内存数据库,就像 memcache 一样。redis持久化RDB RDB 方式,是将 redis 某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。 redis 在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。对于 RDB 方式,redis 会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何 IO 操作的,这样就确保了 redis 极高的性能。 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那 RDB 方式要比 AOF 方式更加的高效。 虽然 RDB 有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么 RDB 方式就不太适合你,因为即使你每 5 分钟都持久化一次,当 redis 故障时,仍然会有近 5 分钟的数据丢失。所以,redis 还提供了另一种持久化方式,那就是 AOF。测试触发机制1、save的规则满足的情况下,会自动触发rdb规则2、执行flushall命令也会触发rdb规则3、退出redis,也会产生rdb文件备份就会自动产生一个dump.rdp如何恢复rdb文件1、只需要rdb文件放在我们redis启动目录就可以了 redis会自动检查dump.rdp恢复其中的数据2、检查需要存在的位置127.0.0.1:6379> config get dir 1) "dir" 2) "/usr/local/bin"优点:适合大规模的数据恢复对数据完整性要求不高缺点:需要一定的时间间隔进程操作,如果redis宕机,这个最好一次修改数据就没有了fork进程的时候,会占用一定的内容空间redis持久化AOF AOF,英文是 Append Only File,即只允许追加不允许改写的文件。 如前面介绍的,AOF 方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍,就这么简单。 我们通过配置 redis.conf 中的 appendonly yes 就可以打开 AOF 功能。如果有写操作(如 SET 等),redis 就会被追加到 AOF 文件的末尾。 默认的 AOF 持久化策略是每秒钟 fsync 一次(fsync 是指把缓存中的写指令记录到磁盘中),因为在这种情况下,redis 仍然可以保持很好的处理性能,即使 redis 故障,也只会丢失最近 1 秒钟的数据。如果在追加日志时,恰好遇到磁盘空间满、inode 满或断电等情况导致日志写入不完整,也没有关系,redis 提供了 redis-check-aof 工具,可以用来进行日志修复。 因为采用了追加方式,如果不做任何处理的话,AOF 文件会变得越来越大,为此,redis 提供了 AOF 文件重写(rewrite)机制,即当 AOF 文件的大小超过所设定的阈值时,redis 就会启动 AOF 文件的内容压缩,只保留可以恢复数据的最小指令集。举个例子或许更形象,假如我们调用了 100 次 INCR 指令,在 AOF 文件中就要存储 100 条指令,但这明显是很低效的,完全可以把这 100 条指令合并成一条 SET 指令,这就是重写机制的原理。在进行 AOF 重写时,仍然是采用先写临时文件,全部完成后再替换的流程,所以断电、磁盘满等问题都不会影响 AOF 文件的可用性,这点大家可以放心。 AOF 方式的另一个好处,我们通过一个“场景再现”来说明。某同学在操作 redis 时,不小心执行了 FLUSHALL,导致 redis 内存中的数据全部被清空了,这是很悲剧的事情。不过这也不是世界末日,只要 redis 配置了 AOF 持久化方式,且 AOF 文件还没有被重写(rewrite),我们就可以用最快的速度暂停 redis 并编辑 AOF 文件,将最后一行的 FLUSHALL 命令删除,然后重启 redis,就可以恢复 redis 的所有数据到 FLUSHALL 之前的状态了。是不是很神奇,这就是 AOF 持久化方式的好处之一。但是如果 AOF 文件已经被重写了,那就无法通过这种方法来恢复数据了。虽然优点多多,但 AOF 方式也同样存在缺陷,比如在同样数据规模的情况下,AOF 文件要比 RDB 文件的体积大。而且,AOF 方式的恢复速度也要慢于 RDB 方式。 如果你直接执行 BGREWRITEAOF 命令,那么 redis 会生成一个全新的 AOF 文件,其中便包括了可以恢复现有数据的最少的命令集。 如果运气比较差,AOF 文件出现了被写坏的情况,也不必过分担忧,redis 并不会贸然加载这个有问题的 AOF 文件,而是报错退出。这时可以通过以下步骤来修复出错的文件:1.备份被写坏的 AOF 文件2.运行 redis-check-aof –fix 进行修复3.用 diff -u 来看下两个文件的差异,确认问题点4.重启 redis,加载修复后的 AOF 文件redis持久化 – AOF重写 AOF 重写的内部运行原理,我们有必要了解一下。 在重写即将开始之际,redis 会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的 AOF 文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。 与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的 AOF 文件中,这样做是保证原有的 AOF 文件的可用性,避免在重写过程中出现意外。 当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新 AOF 文件中。 当追加结束后,redis 就会用新 AOF 文件来代替旧 AOF 文件,之后再有新的写指令,就都会追加到新的 AOF 文件中了。测试如果aof文件有错误,这个时候redis是启动不起来的,需要修复这个aof文件redis-check-aof[root@cs bin]# redis-check-aof --fix appendonly.aof 0x 4: Expected prefix '$', got: 'e' AOF analyzed: size=122, ok_up_to=0, diff=122 This will shrink the AOF from 122 bytes, with 122 bytes, to 0 bytes Continue? [y/N]: y Successfully truncated AOF优点:每次修改都同步,文件的完整性更好每秒同步一次可能会丢失一秒数据从不同步,效率最高缺点:相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢aof运行效率也要比rdb慢 ,所以我们redis默认的配置就是rdb持久化redis持久化 – 如何选择RDB和AOF对于我们应该选择 RDB 还是 AOF,官方的建议是两个同时使用。这样可以提供更可靠的持久化方案。
-
Redis事务 {message type="error" content="Rise单条命令保存原子性,但是事务不保证原子性!"/}Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:批量操作在发送 EXEC 命令前被放入队列缓存。收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。一个事务从开始到执行会经历以下三个阶段:开始事务。(multi)命令入队。执行事务。(exec)正常执行事务127.0.0.1:6379> multi #开启事务 OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> get k2 QUEUED 127.0.0.1:6379> set k3 v3 QUEUED 127.0.0.1:6379> exec #执行事务 1) OK 2) OK 3) "v2" 4) OK放弃事务127.0.0.1:6379> multi OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> set k3 v3 QUEUED 127.0.0.1:6379> DISCARD #取消事务如果编译出现异常(命令输错),事务中的所有命令都不会被执行运行时异常,如果事务队列中存在语法性,那么执行命令时,其他命令是可以正常运行的,错误命令抛出异常监控 watch悲观锁 乐观锁Redis 测试监视测试127.0.0.1:6379> set money 100 OK 127.0.0.1:6379> set out 0 OK 127.0.0.1:6379> watch money #监视 money OK 127.0.0.1:6379> MULTI #事务正常结束,数据期间没有发生变动,这个时候就正常执行成功 OK 127.0.0.1:6379> DECRBY money 20 QUEUED 127.0.0.1:6379> INCRBY out 20 QUEUED 127.0.0.1:6379> exec测试多线程修改值,使用watch可以当作redis的乐观锁操作127.0.0.1:6379> WATCH money #监控 OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> DECRBY money 20 QUEUED 127.0.0.1:6379> INCRBY out 10 QUEUED 127.0.0.1:6379> exec #执行之前,另外一个线程,修改了我们的值,这个时候就会执行失败 (nil)如果修改失败,获取最新的值就好
-
Redis 详解 什么是Redis?redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库。Redis的功能1、持久化2、数据类型丰富3、支持高可用4、支持事务5、多种内存分配及回收策略6、消息队列、消息订阅 7、支持分布式分片集群 8、缓存穿透雪崩9、Redis APIRedis优点优点:高性能读写、多数据类型支持、数据持久化、高可用架构、支持自定义虚拟内存、支持分布式分片集群、单线程读写性能极高适合,少用户访问,每个用户大量rw使用场景Redis:单核的缓存服务,单节点情况下,更加适合于少量用户,多次访问的应用场景。Redis一般是单机多实例架构,配合redis集群出现。redis安装部署官网:https://redis.io[root@cs ~]# cd /home/xiaohei [root@cs ~]# wget https://download.redis.io/releases/redis-5.0.13.tar.gz [root@cs ~]# tar xf redis-5.0.13.tar.gz -C /opt/ 安装:依赖包 [root@cs ~]# yum -y install gcc automake autoconf libtool make [root@cs ~]# cd /opt/redis-5.0.13 [root@cs redis-5.0.13]# make [root@cs redis-5.0.13]# cd /usr/local/bin [root@cs bin]# ll total 33796 -rwxr-xr-x 1 root root 1001112 Aug 5 2020 busybox-x86_64 -rw-r--r-- 1 root root 105 Sep 19 21:57 dump.rdb -rwxr-xr-x 1 root root 4367032 Sep 19 18:54 redis-benchmark -rwxr-xr-x 1 root root 8138736 Sep 19 18:54 redis-check-aof -rwxr-xr-x 1 root root 8138736 Sep 19 18:54 redis-check-rdb -rwxr-xr-x 1 root root 4808256 Sep 19 18:54 redis-cli lrwxrwxrwx 1 root root 12 Sep 19 18:54 redis-sentinel -> redis-server -rwxr-xr-x 1 root root 8138736 Sep 19 18:54 redis-server #在这里我们创建一个自己的目录把redis.conf拷进来(防止玩崩了,可以恢复) [root@cs bin]# mkdir xhconfig [root@cs bin]# cp /opt/redis-5.0.13/redis.conf xhconfig/ #启动redis [root@cs bin]# redis-server xhconfig/redis.conf 25779:C 20 Sep 2021 19:03:28.090 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 25779:C 20 Sep 2021 19:03:28.090 # Redis version=5.0.13, bits=64, commit=00000000, modified=0, pid=25779, just started 25779:C 20 Sep 2021 19:03:28.090 # Configuration loaded [root@cs bin]# redis-cli -p 6379 #redis默认 端口是6379 127.0.0.1:6379> 127.0.0.1:6379> ping PONG # 退出 127.0.0.1:6379> shutdown not connected> exit [root@cs bin]# #环境变量: #vim /etc/profile #export PATH=/data/redis/src:$PATH #source /etc/profile Redis.conf详解单位包含引用其他文件网络bind 127.0.0.1 #绑定的IP protected-mode yes #保护模式 port 6379 #端口通用daemonize yes #守护进程(是否后台运行)默认是no,手动开启 pidfile /var/run/redis_6379.pid #如果我们以守护进程开启,我们需要指定一个pid #日志 # This can be one of: # debug (a lot of information, useful for development/testing) # verbose (many rarely useful info, but not a mess like the debug level) # notice (moderately verbose, what you want in production probably) # warning (only very important / critical messages are logged) loglevel notice logfile "" #日志文件目录 (/var/log/redis.log) databases 16 #数据库的数量 always-show-logo yes #是否显示logo快照持久化,在规定时间,执行了多少操作,则会持久化到文件 .rdb .aofredis 是一个内存数据库,如果没有持久化,那么就会断电及失!# 如果900内 ,至少有一个key进行修改,我们就进行持久化操作 save 900 1 # 如果300内 ,至少有十个key进行修改,我们就进行持久化操作 save 300 10 # 如果60内 ,至少有一千个key进行修改,我们就进行持久化操作 save 60 10000 stop-writes-on-bgsave-error yes #如果持久化出错,是否继续工作 rdbcompression yes #是否压缩rdb文件,需要消耗CPU资源 rdbchecksum yes #保存rdb文件时进行错误的检查校验 dir ./ #保存rdb文件的目录REPLICATION主从配置SECURITY 安全 设置用户密码# 用命令 config set requirepass "123456" #设置redis密码 auth 123456 config get requirepass #获取redis密码CLIENTS 限制maxclients 10000 #redis连接数 maxmemory <bytes> #redis最大内存容量 maxmemory-policy noeviction #内存达到上限之后的处理策略 1、volatile-lru:只对设置了过期时间的key进行LRU(默认值) 2、allkeys-lru : 删除lru算法的key 3、volatile-random:随机删除即将过期key 4、allkeys-random:随机删除 5、volatile-ttl : 删除即将过期的 6、noeviction : 永不过期,返回错误APPEND ONLY MODE aof配置appendonly no #默认不开启,默认使用rdb appendfilename "appendonly.aof" ###持久化文件的名字 # appendfsync always #每次都会执行sync 消耗性能 appendfsync everysec #每秒执行一次sync 可能会丢失这1S数据 # appendfsync no #不执行sync ,这个时候系统会自动同步数据,速度最快Redis 命令在远程服务上执行命令如果需要在远程 redis 服务上执行命令,同样我们使用的也是 redis-cli 命令。语法 $ redis-cli -h host -p port -a passwordRedis性能测试redis-benchmark -h 127.0.0.1 -p 6379 -t set,lpush -n 10000 -q SET: 146198.83 requests per second LPUSH: 145560.41 requests per secondRedis 键(key)127.0.0.1:6379> set mykey xiaohei #创建mykey OK 127.0.0.1:6379> get mykey #获取mykey "xiaohei" 127.0.0.1:6379> del mykey #删除mykey (integer) 1 127.0.0.1:6379> keys * #查看所有键 (empty list or set) 127.0.0.1:6379> set myskey "xiaohei" OK 127.0.0.1:6379> exists myskey #键是否存在 (integer) 1 127.0.0.1:6379> 127.0.0.1:6379> FLUSHALL #清除所有库的键 OK 127.0.0.1:6379> FLUSHDB #清除本库的键 127.0.0.1:6379> set mykey "xiaohei" OK 127.0.0.1:6379> EXPIRE mykey 10 #设置10秒后过期 (integer) 1 127.0.0.1:6379> ttl mykey #显示剩余时间 (integer) 8 127.0.0.1:6379> ttl mykey (integer) 5 127.0.0.1:6379> ttl mykey (integer) 2 127.0.0.1:6379> ttl mykey (integer) -2 127.0.0.1:6379> PERSIST mykey #清除过期时间 (integer) 1 127.0.0.1:6379> ttl mykey (integer) -1 127.0.0.1:6379> move mykey 2 #移动到指定的数据库 (integer) 1 127.0.0.1:6379> keys * (empty list or set) 127.0.0.1:6379> select 2 #进入指定数据库 OK 127.0.0.1:6379[2]> keys * 1) "mykey" 127.0.0.1:6379> set mykey "xiaohei" OK 127.0.0.1:6379> set k1 "hello" OK 127.0.0.1:6379> set k2 "world" OK 127.0.0.1:6379> RANDOMKEY #随机显示一个key "mykey" 127.0.0.1:6379> RANDOMKEY "mykey" 127.0.0.1:6379> RANDOMKEY "k2" 127.0.0.1:6379> RANDOMKEY "mykey" 127.0.0.1:6379> RANDOMKEY "mykey" 127.0.0.1:6379> RANDOMKEY "k2" 127.0.0.1:6379> RANDOMKEY "k1" 127.0.0.1:6379> RENAME k1 kk #修改key名 OK 127.0.0.1:6379> keys * 1) "kk" 2) "k2" 3) "mykey" 127.0.0.1:6379> type mykey #显示key的值的类型 stringRedis 字符串(String)127.0.0.1:6379> SET mykey "This is my test key" OK 127.0.0.1:6379> GETRANGE mykey 0 3 #截取字符串[0,3] "This" 127.0.0.1:6379> GETRANGE mykey 0 -1 #截取全部 "This is my test key" 127.0.0.1:6379> APPEND mykey "hello" #追加,如果这个key不存在则会创建一个key (integer) 24 127.0.0.1:6379> get mykey "This is my test keyhello" 127.0.0.1:6379> STRLEN mykey #返回字符串值的长度 (integer) 24 # !替换 127.0.0.1:6379> set mykey "abcdefg" OK 127.0.0.1:6379> SETRANGE mykey 2 xxx #从第二个开始替换 (integer) 7 127.0.0.1:6379> get mykey "abxxxfg" ################################################################################################### # i++ # 步长 i+= 127.0.0.1:6379> set views 0 #初始量0 OK 127.0.0.1:6379> get views "0" 127.0.0.1:6379> incr views #每次自加1 (integer) 1 127.0.0.1:6379> incr views (integer) 2 127.0.0.1:6379> get views "2" 127.0.0.1:6379> decr views #每次自减1 (integer) 1 127.0.0.1:6379> decr views (integer) 0 127.0.0.1:6379> decr views (integer) -1 127.0.0.1:6379> get views "-1" 127.0.0.1:6379> INCRBY views 10 #指定增量 (integer) 9 127.0.0.1:6379> INCRBY views 10 (integer) 19 127.0.0.1:6379> DECRBY views 5 #指定减量 (integer) 14 ################################################################################################### # setex 设置过期时间 # setnx 不存在再设置 127.0.0.1:6379> SETEX mykey 30 "xiaohei" #设置一个mykey 30秒过期 OK 127.0.0.1:6379> ttl mykey (integer) 25 127.0.0.1:6379> get mykey "xiaohei" 127.0.0.1:6379> setnx k1 "redis" #不存在则创建一个key (integer) 1 127.0.0.1:6379> keys * 1) "k1" 127.0.0.1:6379> ttl mykey (integer) -2 127.0.0.1:6379> setnx k1 "mongodb" #存在则操作失败 (integer) 0 127.0.0.1:6379> get k1 "redis" ################################################################################################### # mset # mget 127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 #创建多个key OK 127.0.0.1:6379> keys * 1) "k3" 2) "k2" 3) "k1" 127.0.0.1:6379> mget k1 k2 k3 #查询多个key 1) "v1" 2) "v2" 3) "v3" 127.0.0.1:6379> msetnx k1 v1 k4 v4 #要么一起成功,要么一起失败 (integer) 0 127.0.0.1:6379> get k4 (nil) #对象 127.0.0.1:6379> set user:1 {name:zhangsan,age:18} #设置一个user:1 对象 值为json字符来保存一个对象 OK 127.0.0.1:6379> get user:1 "{name:zhangsan,age:18}" 127.0.0.1:6379> mset user:1:name lisi user:1:age 18 # 设置一个user:{id}:{filed} OK 127.0.0.1:6379> mget user:1:name user:1:age 1) "lisi" 2) "18" ################################################################################################### getset #先get在set 127.0.0.1:6379> getset db redis #如果不存在值则返回空 (nil) 127.0.0.1:6379> get db "redis" 127.0.0.1:6379> getset db mongodb #如果存在则返回原来的值,在覆盖新的值 "redis" 127.0.0.1:6379> get db "mongodb"数据结构是相同的!string类似的使用场景:value 除了字符串还可以是数字计数器统计多单位的数量粉丝数对象缓存存储Redis 列表(List)Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)127.0.0.1:6379> LPUSH mykey "redis" #将一个或者多个值,插入列表头部(左) (integer) 1 127.0.0.1:6379> LPUSH mykey "mongodb" (integer) 2 127.0.0.1:6379> LPUSH mykey "mysql" (integer) 3 127.0.0.1:6379> LRANGE mykey 0 1 1) "mysql" 2) "mongodb" 127.0.0.1:6379> RPUSH mykey "MariaDB" #将一个或者多个值,插入列表头部(右) (integer) 4 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mysql" 2) "mongodb" 3) "redis" 4) "MariaDB" ################################################################################################### LPOP RPOP 127.0.0.1:6379> LPOP mykey #移除(左) "mysql" 127.0.0.1:6379> RPOP mykey #移除(右) "MariaDB" 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mongodb" 2) "redis" ################################################################################################### LINSDEX 127.0.0.1:6379> LINDEX mykey 0 #通过下标获取list中的某个值 "mongodb" 127.0.0.1:6379> LINDEX mykey 1 "redis" ################################################################################################### LLEN 127.0.0.1:6379> LLEN mykey #获取列表长度 (integer) 3 ################################################################################################### LREM 127.0.0.1:6379> LRANGE mykey 0 -1 #LPUSH 可以出现重复的值 1) "redis" 2) "mongodb" 3) "redis" 4) "mysql" 5) "mongodb" 6) "redis" 127.0.0.1:6379> LREM mykey 1 redis #移除1个redis (integer) 1 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mongodb" 2) "redis" 3) "mysql" 4) "mongodb" 5) "redis" 127.0.0.1:6379> LREM mykey 2 mongodb #移除两个mongodb (integer) 2 127.0.0.1:6379> LRANGE mykey 0 -1 1) "redis" 2) "mysql" 3) "redis" ################################################################################################### LTRIM 127.0.0.1:6379> LRANGE mykey 0 -1 1) "redis" 2) "mysql" 3) "redis" 127.0.0.1:6379> LTRIM mykey 0 1 #修剪,截断 OK 127.0.0.1:6379> LRANGE mykey 0 -1 1) "redis" 2) "mysql" ################################################################################################### RPOPLPUSH 移除列表最后一个,并且移动到新的列表 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mongodb" 2) "redis" 3) "mysql" 127.0.0.1:6379> RPOPLPUSH mykey key #移除列表最后一个,并且移动到新的列表 "mysql" 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mongodb" 2) "redis" 127.0.0.1:6379> LRANGE key 0 -1 1) "mysql" ################################################################################################### LSET 将列表中存在的值替换成另外的一个值,更新操作 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mongodb" 2) "redis" 127.0.0.1:6379> LSET mykey 0 mysql #将列表中存在的值替换成另外的一个值,更新操作(值必须存在,不存在则报错) OK 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mysql" 2) "redis" ################################################################################################### LINSERT #在列表指定值前面或者后面插入一个新值 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mysql" 2) "redis" 127.0.0.1:6379> LINSERT mykey before "redis" "mongodb" #在列表指定值前面插入一个新值 (integer) 3 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mysql" 2) "mongodb" 3) "redis" 127.0.0.1:6379> LINSERT mykey after "redis" "maridb" ##在列表指定值后面插入一个新值 (integer) 4 127.0.0.1:6379> LRANGE mykey 0 -1 1) "mysql" 2) "mongodb" 3) "redis" 4) "maridb"Redis 集合(Set)Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。集合对象的编码可以是 intset 或者 hashtable。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。127.0.0.1:6379> sadd mykey "hello" #set集合中添加值 (integer) 1 127.0.0.1:6379> sadd mykey "xiaohei" (integer) 1 127.0.0.1:6379> sadd mykey "123456" (integer) 1 127.0.0.1:6379> SMEMBERS mykey #查看set的所有值 1) "123456" 2) "xiaohei" 3) "hello" 127.0.0.1:6379> SISMEMBER mykey hello #判断一个值是否存在set集合里面 (integer) 1 127.0.0.1:6379> SISMEMBER mykey world (integer) 0 127.0.0.1:6379> SCARD mykey #判断set集合里面的元素个数 (integer) 3 127.0.0.1:6379> SREM mykey 123456 #移除一个元素 (integer) 1 127.0.0.1:6379> SMEMBERS mykey 1) "xiaohei" 2) "hello" 127.0.0.1:6379> SRANDMEMBER mykey #随机显示一个元素 "xiaohei" 127.0.0.1:6379> SRANDMEMBER mykey "hello" 127.0.0.1:6379> sadd mykey "xiaohei" "hello" "world" (integer) 3 127.0.0.1:6379> SMEMBERS mykey 1) "world" 2) "hello" 3) "xiaohei" 127.0.0.1:6379> spop mykey #随机删除一个元素 "world" 127.0.0.1:6379> spop mykey "xiaohei" 127.0.0.1:6379> SMEMBERS mykey 1) "hello" ################################################################################### 127.0.0.1:6379> sadd mykey "xiaohei" "hello" "world" (integer) 3 127.0.0.1:6379> SMEMBERS mykey 1) "world" 2) "hello" 3) "xiaohei" 127.0.0.1:6379> sadd k1 "12345" "abcdefg" (integer) 2 127.0.0.1:6379> SMEMBERS k1 1) "12345" 2) "abcdefg" 127.0.0.1:6379> SMOVE mykey k1 xiaohei #指定一个元素,移动到另一个集合 (integer) 1 127.0.0.1:6379> SMEMBERS k1 1) "12345" 2) "abcdefg" 3) "xiaohei" 127.0.0.1:6379> SMEMBERS mykey 1) "world" 2) "hello" ################################################################################### 127.0.0.1:6379> SMEMBERS mykey 1) "world" 2) "xiaohei" 3) "hello" 127.0.0.1:6379> SMEMBERS k1 1) "12345" 2) "abcdefg" 3) "xiaohei" 127.0.0.1:6379> sinter mykey k1 #显示共同的值(交) 1) "xiaohei" 127.0.0.1:6379> sunion mykey k1 #显示不相同的值(并) 1) "world" 2) "hello" 3) "xiaohei" 4) "12345" 5) "abcdefg"Redis 哈希(Hash)Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。127.0.0.1:6379> hset myhash field1 xiaohei #set一个值 (integer) 1 127.0.0.1:6379> hget myhash field1 #获取一个字段的值 "xiaohei" 127.0.0.1:6379> hmset myhash field1 hello field2 world #set多个值 OK 127.0.0.1:6379> hmget myhash field1 field2 #获取多个值 1) "hello" 2) "world" 127.0.0.1:6379> hgetall myhash #获取全部元素 1) "field1" 2) "hello" 3) "field2" 4) "world" ################################################################################### 127.0.0.1:6379> hdel myhash field2 #删除字段 (integer) 1 127.0.0.1:6379> hgetall myhash 1) "field1" 2) "hello" ################################################################################### 127.0.0.1:6379> hgetall myhash 1) "field1" 2) "hello" 127.0.0.1:6379> hlen myhash #获取hash表的字段数量 (integer) 1 ################################################################################### 127.0.0.1:6379> HEXISTS myhash field1 #判断hash表中是否存在字段 (integer) 1 127.0.0.1:6379> HEXISTS myhash field2 (integer) 0 ################################################################################### 127.0.0.1:6379> hkeys myhash #获取所有field 1) "field1" 127.0.0.1:6379> hvals myhash #获取所有value 1) "hello" ################################################################################### 127.0.0.1:6379> hset myhash field3 5 #指定增量 (integer) 1 127.0.0.1:6379> HINCRBY myhash field3 1 (integer) 6 127.0.0.1:6379> HINCRBY myhash field3 1 (integer) 7 127.0.0.1:6379> HINCRBY myhash field3 -1 (integer) 6 127.0.0.1:6379> HSETNX myhash field4 hello #如果不存在则创建 (integer) 1 127.0.0.1:6379> HSETNX myhash field4 world #存在则失败 (integer) 0hash变更的数据 user name age ,尤其是用户信息之类的,经常变动的信息hashsh更适合对象存储zset(有序集合)127.0.0.1:6379> zadd myset 1 one #添加值 (integer) 1 127.0.0.1:6379> zadd myset 2 two 3 tree #添加多个值 (integer) 2 127.0.0.1:6379> ZRANGE myset 0 -1 1) "one" 2) "two" 3) "tree" ################################################################################### 排序 127.0.0.1:6379> zadd salary 2500 xiaohong #创建三个用户 (integer) 1 127.0.0.1:6379> zadd salary 5000 zhangsan 500lisi (error) ERR syntax error 127.0.0.1:6379> zadd salary 5000 zhangsan (integer) 1 127.0.0.1:6379> zadd salary 500 lisi (integer) 1 127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf #显示全部,从小到大排序 1) "lisi" 2) "xiaohong" 3) "zhangsan" 127.0.0.1:6379> ZREVRANGE salary 0 -1 #从大到小 1) "zhangsan" 2) "lisi" 127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores ##显示全部,并且附带 1) "lisi" 2) "500" 3) "xiaohong" 4) "2500" 5) "zhangsan" 6) "5000" 127.0.0.1:6379> ZRANGEBYSCORE salary -inf 2500 withscores ##显示到2500的用户 1) "lisi" 2) "500" 3) "xiaohong" 4) "2500" ################################################################################### 127.0.0.1:6379> ZRANGE salary 0 -1 1) "lisi" 2) "xiaohong" 3) "zhangsan" 127.0.0.1:6379> ZREM salary xiaohong #移除有序集合的指定元素 (integer) 1 127.0.0.1:6379> ZRANGE salary 0 -1 1) "lisi" 2) "zhangsan" 127.0.0.1:6379> ZCARD salary #获取有序集合的元素个数 (integer) 2 ################################################################################### 127.0.0.1:6379> zadd k1 1 hello 2 world 3 xiaohei (integer) 3 127.0.0.1:6379> ZCOUNT k1 1 3 #获取指定区间的成员数量 (integer) 3 127.0.0.1:6379> ZCOUNT k1 1 2 (integer) 2
-
Linux一键重装脚本,Centos、Debain、Ubuntu随意选择 今天分享一下脚本,可以一键安装Centos、Debain、Ubuntu三种系统,而且可以选择各种版本的系统,同时还支持自定义系统,有需要的朋友可以试试.支持重装的系统Debian 9/10 Ubuntu 18.04/16.04 CentOS 6/7特点自动获取IP地址、网关、子网掩码自动判断网络环境,选择国内/外镜像,再也不用担心卡半天了超级懒人一键化,无需复杂的命令解决萌咖脚本中一些导致安装错误的问题CentOS 7 镜像抛弃LVM,回归ext4,减少不稳定因素一键脚本wget --no-check-certificate -O AutoReinstall.sh https://git.io/AutoReinstall.sh && bash AutoReinstall.sh执行效果如下,可以选择各种Linux发行版本,8是自定义系统
-
MySQL备份恢复 mysqldump命令{alert type="info"}逻辑备份工具。文本形式保存备份,可读性较强。备份逻辑: 将建库、建表、数据插入语句导出,包存至一个sql文件中。比较适合于:数据量较小的场景,单表数据行千万级别以内。百G以内的小型数据库.跨版本、跨平台迁移。可以本地、可以远程备份。注意: 一般情况下,恢复需要耗费的时间是备份耗费时间的3-5倍。{/alert}连接参数:mysqldump -u -p -S -h -P{message type="info" content="-u 用户-p 密码-S 指定连接mysql的socket文件位置,默认路径/tmp/mysql.sock-h IP地址-P 端口(默认3306)"/}备份参数:-A:全备份[root@cs ~]# mysqldump -uroot -p123 -A >/data/backup/full.sql-B:单库或者多库备份[root@cs ~]# mysqldump -uroot -p123 -B test cs >/data/backup/db.sql单表或者多表备份[root@cs ~]# mysqldump -uroot -p123 -B world city country >/data/backup/biao.sql{alert type="warning"}注意:-A 和 -B 都带有了 create database 和use 语句,直接恢复即可单表或多表备份方式, 没有 create database 和use 语句,所以要手工进行建库和use,再恢复数据。{/alert}高级功能参数参数一: --master-data=2自动记录binlog位置点 b. 自动加GRL锁(FTWRL ,flush tables with read lock) c. 配合--single-transaction ,减少锁的时间。参数二: single-transaction对于InnoDB表,利用MVCC中一致性快照进行备份。备份数据时,不加锁 b. 备份期间如果出现DDL操作,导致备份数据不一致 问题: mysqldump是严格意义上的热备吗? 8.0 之后 master-data和single-transaction,对于InnoDB数据备份时是快照备份的. 备份表结构等数据时,还是FTWRL过程备份. --single-transaction 只是针对InnoDB表数据进行一致性快照备份。 问题: mysqldump备份需要锁表吗? 是有的。global read lock参数三: -R -E --triggers 备份特殊对象存储过程 函数 触发器 事件参数四: --max_allowed_packet=64M最大允许数据包的大小。标准化备份[root@cs backup]# mysqldump -uroot -p -A --master-data=2 --single-transaction -R -E --triggers --max_allowed_packet=64M >/data/backup/full_`date +%F`.sql Enter password: 实验:通过mysqldump全备+binlog实现PIT数据恢复{alert type="info"}环境背景: 小型的业务数据库,50G,每天23:00全备,定期binlog异地备份。故障场景: 周三下午2点,开发Navicat连接数据库实例错误,导致生产数据被误删除(DROP)恢复思路:挂维护页。检查备份、日志可用。如果只是部分损坏,建议找一个应急库进行恢复全备恢复日志截取并恢复恢复后数据校验 (业务测试部门验证)立即备份(停机冷备)恢复架构系统撤维护页,恢复业务{/alert}环境搭建mysql> create database mdb; Query OK, 1 row affected (0.00 sec) mysql> use mdb; Database changed mysql> create table t1 (id int); Query OK, 0 rows affected (0.03 sec) mysql> create table t2 (id int); Query OK, 0 rows affected (0.03 sec) mysql> create table t3 (id int); Query OK, 0 rows affected (0.03 sec) mysql> insert into t1 values(1),(2),(3); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> insert into t2 values(1),(2),(3); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> insert into t3 values(1),(2),(3); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) [root@cs ~]# mysqldump -uroot -p -A --master-data=2 --single-transaction -R -E --triggers --max_allowed_packet=64M >/tmp/full_`date +%F`.sql Enter password: mysql> create table t4 (id int); Query OK, 0 rows affected (0.09 sec) mysql> insert into t4 values (1),(2),(3); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> drop database mdb; Query OK, 4 rows affected (0.06 sec)恢复过程查看备份获取二进制位置点mysql> show binary logs; +------------------+-----------+ | Log_name | File_size | +------------------+-----------+ | mysql-bin.000001 | 177 | | mysql-bin.000002 | 201 | | mysql-bin.000003 | 201 | | mysql-bin.000004 | 3513 | +------------------+-----------+ 4 rows in set (0.00 sec) mysql> show binlog events in 'mysql-bin.000004'; +------------------+------+----------------+-----------+-------------+---------------------------------- | Log_name | Pos | Event_type | Server_id | End_log_pos | Info +------------------+------+----------------+-----------+-------------+---------------------------------- |........................................................................................................ | mysql-bin.000004 | 1580 | Query | 1 | 1671 | create database mdb | | mysql-bin.000004 | 1671 | Anonymous_Gtid | 1 | 1736 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 1736 | Query | 1 | 1832 | use `mdb`; create table t1 (id int) | | mysql-bin.000004 | 1832 | Anonymous_Gtid | 1 | 1897 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 1897 | Query | 1 | 1993 | use `mdb`; create table t2 (id int) | | mysql-bin.000004 | 1993 | Anonymous_Gtid | 1 | 2058 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 2058 | Query | 1 | 2154 | use `mdb`; create table t3 (id int) | | mysql-bin.000004 | 2154 | Anonymous_Gtid | 1 | 2219 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 2219 | Query | 1 | 2290 | BEGIN | | mysql-bin.000004 | 2290 | Table_map | 1 | 2334 | table_id: 131 (mdb.t1) | | mysql-bin.000004 | 2334 | Write_rows | 1 | 2384 | table_id: 131 flags: STMT_END_F | | mysql-bin.000004 | 2384 | Xid | 1 | 2415 | COMMIT /* xid=1405 */ | | mysql-bin.000004 | 2415 | Anonymous_Gtid | 1 | 2480 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 2480 | Query | 1 | 2551 | BEGIN | | mysql-bin.000004 | 2551 | Table_map | 1 | 2595 | table_id: 132 (mdb.t2) | | mysql-bin.000004 | 2595 | Write_rows | 1 | 2645 | table_id: 132 flags: STMT_END_F | | mysql-bin.000004 | 2645 | Xid | 1 | 2676 | COMMIT /* xid=1406 */ | | mysql-bin.000004 | 2676 | Anonymous_Gtid | 1 | 2741 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 2741 | Query | 1 | 2812 | BEGIN | | mysql-bin.000004 | 2812 | Table_map | 1 | 2856 | table_id: 133 (mdb.t3) | | mysql-bin.000004 | 2856 | Write_rows | 1 | 2906 | table_id: 133 flags: STMT_END_F | | mysql-bin.000004 | 2906 | Xid | 1 | 2937 | COMMIT /* xid=1407 */ | | mysql-bin.000004 | 2937 | Anonymous_Gtid | 1 | 3002 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 3002 | Query | 1 | 3098 | use `mdb`; create table t4 (id int) | | mysql-bin.000004 | 3098 | Anonymous_Gtid | 1 | 3163 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 3163 | Query | 1 | 3234 | BEGIN | | mysql-bin.000004 | 3234 | Table_map | 1 | 3278 | table_id: 366 (mdb.t4) | | mysql-bin.000004 | 3278 | Write_rows | 1 | 3328 | table_id: 366 flags: STMT_END_F | | mysql-bin.000004 | 3328 | Xid | 1 | 3359 | COMMIT /* xid=4749 */ | | mysql-bin.000004 | 3359 | Anonymous_Gtid | 1 | 3424 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 3424 | Query | 1 | 3513 | drop database mdb | +------------------+------+----------------+-----------+-------------+---------------------------------------+ 恢复备份 mysql> source /tmp/full_2021-08-25.sql; 二进制恢复 [root@cs tmp]# mysqlbinlog --skip-gtids --start-position=1580 --stop-position=3424 /var/lib/mysql/mysql-bin.000004 >/tmp/bin1.sql mysql> set sql_log_bin=0; mysql> source /tmp/bin.sql mysql> set sql_log_bin=1;{alert type="warning"}100G mysqldump全备恢复时间很长,误删除的表10M大小 ,有什么思路可以快速恢复?思路: a. 从全备中,将单表 建表语句和insert语句提取出来 ,进行恢复 sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `oldguo`/!d;q' /data/backup/mdp/full.sql>/data/createtable.sql grep -i 'INSERT INTO `oldguo`' /data/backup/mdp/full.sql >/data/data.sql b. 从binlog中单独截取单表的所有binlog,进行恢复。 binlog2sql 截取单表binlog,恢复。{/alert}物理备份工具使用-Percona Xtrabackup(PXB){alert type="info"}物理备份工具,支持全备和增量备份。备份逻辑:数据库运行期间,拷贝数据表空间.拷贝的同时,会将备份期间的redo进行备份恢复逻辑 :模拟了InnoDB Crash Recovery 功能,需要要将备份进行处理(前滚和回滚)后才能恢复{/alert}安装yum 源[root@cs ~]# yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm -y安装XtraBackup 2.4版本的[root@cs ~]# yum install -y percona-xtrabackup-24.x86_641.全量备份[root@cs backup]# innobackupex --user=root --password=123 /tmp/backup &>/tmp/xbk.log自主定制备份路径名[root@cs backup]# innobackupex --user=root --password=123 --no-timestamp /data/backup/full &>/tmp/xbk.log全备的恢复准备备份(Prepared)将redo进行重做,已提交的写到数据文件,未提交的使用undo回滚掉。模拟了CSR的过程[root@cs lib]# innobackupex --apply-log /tmp/backup/full/恢复备份前提:1、被恢复的目录是空 2、被恢复的数据库的实例是关闭 systemctl stop mysqld创建新目录[root@cs backup]# mkdir /var/lib/mysql数据拷贝[root@cs lib]# innobackupex --copy-back /tmp/backup/full/启动数据库systemctl start mysqldinnobackupex 增量备份(incremental)(1)增量备份的方式,是基于上一次备份进行增量。 (2)增量备份无法单独恢复。必须基于全备进行恢复。 (3)所有增量必须要按顺序合并到全备中。前期准备mysql> create database test charset utf8; Query OK, 1 row affected (0.01 sec) mysql> use test; Database changed mysql> create table t1 (id int); Query OK, 0 rows affected (0.03 sec) mysql> insert into t1 values(1),(2),(3); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from t1; +------+ | id | +------+ | 1 | | 2 | | 3 | +------+ 3 rows in set (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec)增量备份命令# 全备 (周日) [root@cs tmp]# innobackupex --user=root --password=123 --no-timestamp /tmp/backup/full &> /tmp/xbk.log # 模拟数据变化 (周一) mysql> create database cs; Query OK, 1 row affected (0.00 sec) mysql> use cs; Database changed mysql> create table t1 (id int); Query OK, 0 rows affected (0.03 sec) mysql> insert into t1 values (1),(2),(3); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) #周一备份 [root@cs tmp]# innobackupex --user=root --password=123 --no-timestamp --incremental /tmp/backup/inc1 --incremental-basedir=/tmp/backup/full &>/tmp/inc1.log #模拟周二数据(cs) mysql> create table t2 (id int); Query OK, 0 rows affected (0.03 sec) mysql> insert into t2 values(1),(2),(3); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) #周二备份 [root@cs backup]# innobackupex --user=root --password=123 --no-timestamp --incremental /tmp/backup/inc2 --incremental-basedir=/tmp/backup/inc1 &>/tmp/inc2.log # 模拟周三数据变化 mysql> create table t3 (id int); Query OK, 0 rows affected (0.02 sec) mysql> insert into t3 values(1),(2),(3); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> drop database cs; Query OK, 3 rows affected (0.04 sec)恢复到周三误drop之前的数据状态恢复思路: 1. 挂出维护页,停止当天的自动备份脚本 2. 检查备份:周日full+周一inc1+周二inc2,周三的完整二进制日志 3. 进行备份整理(细节),截取关键的二进制日志(从备份——误删除之前) 4. 测试库进行备份恢复及日志恢复 5. 应用进行测试无误,开启业务 6. 此次工作的总结开始恢复(1) 全备的整理 [root@cs backup]# innobackupex --apply-log --redo-only /tmp/backup/full/ (2) 合并inc1到full中 [root@cs backup]# innobackupex --apply-log --redo-only --incremental-dir=/tmp/backup/inc1 /tmp/backup/full/ (3) 合并inc2到full中 [root@cs backup]# innobackupex --apply-log --incremental-dir=/tmp/backup/inc2 /tmp/backup/full/ (4) 最后一次整理全备 [root@cs backup]# innobackupex --apply-log /tmp/backup/full (5) 二进制截取 判断起点 [root@cs backup]# cat inc2/xtrabackup_binlog_info mysql-bin.000001 2463 判断终点 mysql> show binlog events in 'mysql-bin.000001'; +------------------+------+----------------+-----------+-------------+---------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +------------------+------+----------------+-----------+-------------+---------------------------------------+ | mysql-bin.000001 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.34-log, Binlog ver: 4 | | mysql-bin.000001 | 123 | Previous_gtids | 1 | 154 | | | mysql-bin.000001 | 154 | Anonymous_Gtid | 1 | 219 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 219 | Query | 1 | 326 | create database test charset utf8 | | mysql-bin.000001 | 326 | Anonymous_Gtid | 1 | 391 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 391 | Query | 1 | 489 | use `test`; create table t1 (id int) | | mysql-bin.000001 | 489 | Anonymous_Gtid | 1 | 554 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 554 | Query | 1 | 626 | BEGIN | | mysql-bin.000001 | 626 | Table_map | 1 | 671 | table_id: 122 (test.t1) | | mysql-bin.000001 | 671 | Write_rows | 1 | 721 | table_id: 122 flags: STMT_END_F | | mysql-bin.000001 | 721 | Xid | 1 | 752 | COMMIT /* xid=68 */ | | mysql-bin.000001 | 752 | Anonymous_Gtid | 1 | 817 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 817 | Query | 1 | 905 | create database cs | | mysql-bin.000001 | 905 | Anonymous_Gtid | 1 | 970 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 970 | Query | 1 | 1064 | use `cs`; create table t1 (id int) | | mysql-bin.000001 | 1064 | Anonymous_Gtid | 1 | 1129 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 1129 | Query | 1 | 1199 | BEGIN | | mysql-bin.000001 | 1199 | Table_map | 1 | 1242 | table_id: 123 (cs.t1) | | mysql-bin.000001 | 1242 | Write_rows | 1 | 1292 | table_id: 123 flags: STMT_END_F | | mysql-bin.000001 | 1292 | Xid | 1 | 1323 | COMMIT /* xid=81 */ | | mysql-bin.000001 | 1323 | Anonymous_Gtid | 1 | 1388 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 1388 | Query | 1 | 1474 | drop database cs | | mysql-bin.000001 | 1474 | Anonymous_Gtid | 1 | 1539 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 1539 | Query | 1 | 1627 | create database cs | | mysql-bin.000001 | 1627 | Anonymous_Gtid | 1 | 1692 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 1692 | Query | 1 | 1786 | use `cs`; create table t1 (id int) | | mysql-bin.000001 | 1786 | Anonymous_Gtid | 1 | 1851 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 1851 | Query | 1 | 1921 | BEGIN | | mysql-bin.000001 | 1921 | Table_map | 1 | 1964 | table_id: 423 (cs.t1) | | mysql-bin.000001 | 1964 | Write_rows | 1 | 2014 | table_id: 423 flags: STMT_END_F | | mysql-bin.000001 | 2014 | Xid | 1 | 2045 | COMMIT /* xid=113 */ | | mysql-bin.000001 | 2045 | Anonymous_Gtid | 1 | 2110 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 2110 | Query | 1 | 2204 | use `cs`; create table t2 (id int) | | mysql-bin.000001 | 2204 | Anonymous_Gtid | 1 | 2269 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 2269 | Query | 1 | 2339 | BEGIN | | mysql-bin.000001 | 2339 | Table_map | 1 | 2382 | table_id: 728 (cs.t2) | | mysql-bin.000001 | 2382 | Write_rows | 1 | 2432 | table_id: 728 flags: STMT_END_F | | mysql-bin.000001 | 2432 | Xid | 1 | 2463 | COMMIT /* xid=136 */ | | mysql-bin.000001 | 2463 | Anonymous_Gtid | 1 | 2528 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 2528 | Query | 1 | 2622 | use `cs`; create table t3 (id int) | | mysql-bin.000001 | 2622 | Anonymous_Gtid | 1 | 2687 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 2687 | Query | 1 | 2757 | BEGIN | | mysql-bin.000001 | 2757 | Table_map | 1 | 2800 | table_id: 1034 (cs.t3) | | mysql-bin.000001 | 2800 | Write_rows | 1 | 2850 | table_id: 1034 flags: STMT_END_F | | mysql-bin.000001 | 2850 | Xid | 1 | 2881 | COMMIT /* xid=159 */ | | mysql-bin.000001 | 2881 | Anonymous_Gtid | 1 | 2946 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000001 | 2946 | Query | 1 | 3032 | drop database cs | +-----------------+------+----------------+-----------+-------------+---------------------------------------+ 恢复3. 截取周二 23:00 到drop 之前的 binlog [root@cs backup]# mysqlbinlog --start-position=2463 --stop-position=2946 /var/lib/mysql/mysql-bin.000001 >/tmp/backup/bin.sql 4. 进行恢复 [root@cs lib]# innobackupex --copy-back /tmp/backup/full/ [root@cs lib]# chown -R mysql.mysql mysql [root@cs lib]# systemctl start mysqld 二进制恢复 mysql> set sql_log_bin=0; Query OK, 0 rows affected (0.00 sec) mysql> source /tmp/backup/bin.sql; Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Database changed Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Charset changed Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected, 1 warning (0.00 sec) Query OK, 0 rows affected (0.03 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) mysql> show tables; +--------------+ | Tables_in_cs | +--------------+ | t1 | | t2 | | t3 | +--------------+ 3 rows in set (0.00 sec) mysql> set sql_log_bin=1;
-
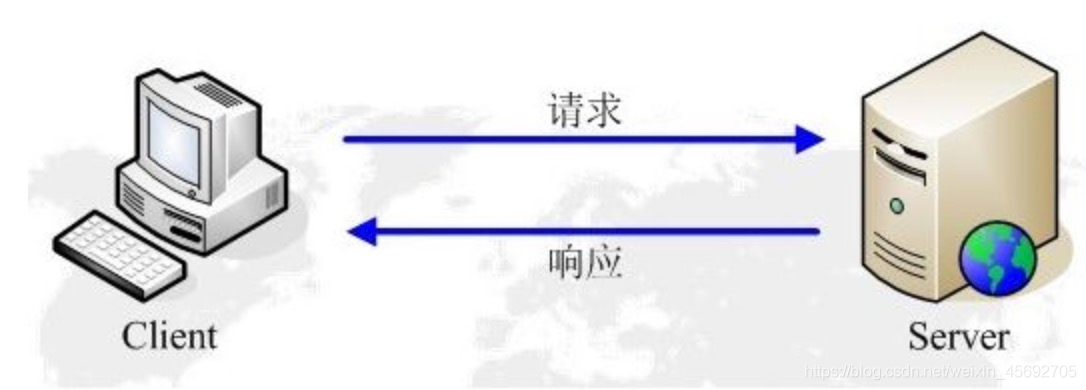
你真的了解http与https吗? HTTP协议简介HTTP协议(超文本传输协议HyperText Transfer Protocol),它是基于TCP协议的应用层传输协议,简单来说就是客户端和服务端进行数据传输的一种规则。注意: 客户端与服务器的角色不是固定的,一端充当客户端,也可能在某次请求中充当服务器。这取决与请求的发起端。HTTP协议属于应用层,建立在传输层协议TCP之上。客户端通过与服务器建立TCP连接,之后发送HTTP请求与接收HTTP响应都是通过访问Socket接口来调用TCP协议实现。HTTP 是一种无状态 (stateless) 协议, HTTP协议本身不会对发送过的请求和相应的通信状态进行持久化处理。这样做的目的是为了保持HTTP协议的简单性,从而能够快速处理大量的事务, 提高效率。协议协议规定了通信双方必须遵循的数据传输格式,这样通信双方按照约定的格式才能准确的通信。无状态无状态是指两次连接通信之间是没有任何关系的,每次都是一个新的连接,服务端不会记录前后的请求信息。七层网络模型HTTP工作原理HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。以下是 HTTP 请求/响应的步骤:客户端连接到Web服务器:一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.baidu.com。发送HTTP请求:通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。服务器接受请求并返回HTTP响应:Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。释放连接TCP连接:若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;客户端浏览器解析HTML内容:客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;释放 TCP连接;浏览器将该 html 文本并显示内容;http协议是基于TCP/IP协议之上的应用层协议。`基于 请求-响应 的模式HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并 返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有 接收到请求之前不会发送响应。无状态保存HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个 级别,协议对于发送过的请求或响应都不做持久化处理。使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产 生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把HTTP协议设计成 如此简单的。可是,随着Web的不断发展,因无状态而导致业务处理变得棘手 的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的 其他页面后,也需要能继续保持登录状态。针对这个实例,网站为了能 够掌握是谁送出的请求,需要保存用户的状态。HTTP/1.1虽然是无状态协议,但为了实现期望的保持状态功能, 于是引入了Cookie技术。有了Cookie再用HTTP协议通信,就可以管 理状态了。有关Cookie的详细内容稍后讲解。无连接无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间,并且可以提高并发性能,不能和每个用户建立长久的连接,请求一次相应一次,服务端和客户端就中断了。但是无连接有两种方式,早期的http协议是一个请求一个响应之后,直接就断开了,但是现在的http协议1.1版本不是直接就断开了,而是等几秒钟,这几秒钟是等什么呢,等着用户有后续的操作,如果用户在这几秒钟之内有新的请求,那么还是通过之前的连接通道来收发消息,如果过了这几秒钟用户没有发送新的请求,那么就会断开连接,这样可以提高效率,减少短时间内建立连接的次数,因为建立连接也是耗时的,默认的好像是3秒中现在,但是这个时间是可以通过咱们后端的代码来调整的,自己网站根据自己网站用户的行为来分析统计出一个最优的等待时间。HTTP的五大特点支持客户/服务器模式。简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。早期这么做的原因是请求资源少,追求快。后来通过Connection: Keep-Alive实现长连接无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。URI和URL的区别URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的URI一般由三部组成:访问资源的命名机制存放资源的主机名资源自身的名称,由路径表示,着重强调于资源。URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成:协议(或称为服务方式)存有该资源的主机IP地址(有时也包括端口号)主机资源的具体地址。如目录和文件名等URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如 mailto:java-net@java.sun.com。URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例。在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。相反的是,URL类可以打开一个到达资源的流。URLHTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息。URL构成URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。从上面的URL可以看出,一个完整的URL包括以下几部分:协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符。 域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用.端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口 (这里的链接就采用的默认端口)虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中没有虚拟目录。文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“weixin_45692705”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名。锚部分:从“#”开始到最后,都是锚部分。本例中没有锚部分。锚部分也不是一个URL必须的部分.参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“spm=1011.2124.3001.5343”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。请求消息Request客户端发送一个HTTP请求到服务器的请求消息包括以下格式: 请求行,请求头,请求体Http请求消息结构请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本。GET说明请求类型为GET,[/department/87423/users]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息。从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等第三部分:空行,请求头部后面的空行是必须的。即使第四部分的请求数据为空,也必须有空行。第四部分:请求数据也叫主体,可以添加任意的其他数据。这个例子的请求数据为name=flyhero。响应消息Response一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。服务端响应客户端格式:状态行,响应头,响应体 Http响应消息结构 第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)第二部分:消息报头,用来说明客户端要使用的一些附加信息 第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8第三部分:空行,消息报头后面的空行是必须的第四部分:响应正文,服务器返回给客户端的文本信息。 {“name”:“flyhero”,“id”:“push-code”}状态码HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:| 分类 | 分类描述 |1**信息,服务器收到请求,需要请求者继续执行操作2**成功,操作被成功接收并处理3**重定向,需要进一步的操作以完成请求4**客户端错误,请求包含语法错误或无法完成请求5**服务器错误,服务器在处理请求的过程中发生了错误更详细的状态码可查看 HTTP状态码:https://www.runoob.com/http/http-status-codes.html但一般我们只需要知道几个常见的就行,比如 :200:客户端请求成功400:客户端请求有语法错误,不能被服务器所理解401:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用403:服务器收到请求,但是拒绝提供服务404:请求资源不存在,eg:输入了错误的URL500:服务器发生不可预期的错误502:服务器当前不能处理客户端的请求,一段时间后可能恢复正常请求方法截止到HTTP1.1共有下面几种方法方法描述GETGET请求会显示请求指定的资源。一般来说GET方法应该只用于数据的读取,而不应当用于会产生副作用的非幂等的操作中。它期望的应该是而且应该是安全的和幂等的。这里的安全指的是,请求不会影响到资源的状态。POST向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。PUTPUT请求会身向指定资源位置上传其最新内容,PUT方法是幂等的方法。通过该方法客户端可以将指定资源的最新数据传送给服务器取代指定的资源的内容。PATCHPATCH方法出现的较晚,它在2010年的RFC 5789标准中被定义。PATCH请求与PUT请求类似,同样用于资源的更新。二者有以下两点不同:1.PATCH一般用于资源的部分更新,而PUT一般用于资源的整体更新。2.当资源不存在时,PATCH会创建一个新的资源,而PUT只会对已在资源进行更新。DELETEDELETE请求用于请求服务器删除所请求URI(统一资源标识符,Uniform Resource Identifier)所标识的资源。DELETE请求后指定资源会被删除,DELETE方法也是幂等的。OPTIONS允许客户端查看服务器的性能。CONNECTHTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。HEAD类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头。TRACE回显服务器收到的请求,主要用于测试或诊断。注意事项:方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的。当然,所有的方法支持的实现都应当匹配下述的方法各自的语义定义。此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法。例如PATCH(由 RFC 5789 指定的方法)用于将局部修改应用到资源。GET和POST请求的区别GET请求GET /books/?sex=man&name=Professional HTTP/1.1 Host: www.wrox.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6) Gecko/20050225 Firefox/1.0.1 Connection: Keep-Alive 注意最后一行是空行POST请求POST / HTTP/1.1 Host: www.wrox.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6) Gecko/20050225 Firefox/1.0.1 Content-Type: application/x-www-form-urlencoded Content-Length: 40 Connection: Keep-Alive name=Professional%20Ajax&publisher=Wiley 1. GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变2. 传输数据的大小首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。而在实际开发中存在的限制主要有:GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系 统的支持。因此对于GET提交时,传输数据就会受到URL长度的 限制。POST:由于不是通过URL传值,理论上数据不受 限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。3. 安全性POST的安全性要比GET的安全性高。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存;(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击4. Http get,post,soap协议都是在http上运行的get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的查询字符串的长度受到web浏览器和web服务器的限制(如IE最多支持2048个字符),不适合传输大型数据集同时,它很不安全post:请求参数是在http标题的一个不同部分(名为entity body)传输的,这一部分用来传输表单信息,因此必须将Content-type设置为:application/x-www-form- urlencoded。post设计用来支持web窗体上的用户字段,其参数也是作为key/value对传输。但是:它不支持复杂数据类型,因为post没有定义传输数据结构的语义和规则。soap:是http post的一个专用版本,遵循一种特殊的xml消息格式Content-type设置为: text/xml 任何数据都可以xml化。Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.我们看看GET和POST的区别GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.*请求和响应常见通用头名称作用Content-Type请求体/响应体的类型,如:text/html、application/jsonAccept说明接收的类型,可以多个值,用,(半角逗号)分开Content-Length请求体/响应体的长度,单位字节Content-Encoding请求体/响应体的编码格式,如gzip,deflateAccept-Encoding告知对方我方接受的Content-EncodingETag给当前资源的标识,和Last-Modified、If-None-Match、If-Modified-Since配合,用于缓存控制Cache-Control取值为一般为no-cache或max-age=XX,XX为个整数,表示该资源缓存有效期(秒)注意:Content-Type,内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件。常见的媒体格式类型如下:Content-Type(Mime-Type)描述text/htmlHTML格式text/plain纯文本格式text/xmlXML格式image/gifgif图片格式image/jpegjpg图片格式image/pngpng图片格式以application开头的媒体格式类型:Content-Type(Mime-Type)描述application/xmlXML数据格式application/jsonJSON数据格式application/pdfpdf格式application/mswordWord文档格式application/octet-stream二进制流数据(如常见的文件下载)application/x-www-form-urlencodedform表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)multipart/form-data需要在表单中进行文件上传时,就需要使用该格式请求头名称作用Authorization用于设置身份认证信息User-Agent用户标识,如:OS和浏览器的类型和版本If-Modified-Since值为上一次服务器返回的 Last-Modified 值,用于确认某个资源是否被更改过,没有更改过(304)就从缓存中读取If-None-Match值为上一次服务器返回的 ETag 值,一般会和If-Modified-Since一起出现Cookie已有的CookieReferer表示请求引用自哪个地址,比如你从页面A跳转到页面B时,值为页面A的地址Host请求的主机和端口号常见响应头名称作用Date服务器的日期Last-Modified该资源最后被修改时间Transfer-Encoding取值为一般为chunked,出现在Content-Length不能确定的情况下,表示服务器不知道响应版体的数据大小,一般同时还会出现Content-Encoding响应头Set-Cookie设置CookieLocation重定向到另一个URL,如输入浏览器就输入baidu.com回车,会自动跳到 https://www.baidu.com ,就是通过这个响应头控制的Server后台服务器HTTP的不足通信使用明文(不加密),内容可能会被窃听不验证通信方的身份,因此有可能遭遇伪装无法证明报文的完整性,所以有可能已遭篡改非持久连接和持久连接在实际的应用中,客户端往往会发出一系列请求,接着服务器端对每个请求进行响应。对于这些请求|响应,如果每次都经过一个单独的TCP连接发送,称为非持久连接。反之,如果每次都经过相同的TCP连接进行发送,称为持久连接。非持久连接在每次请求|响应之后都要断开连接,下次再建立新的TCP连接,这样就造成了大量的通信开销。例如前面提到的往返时间(RTT) 就是在建立TCP连接的过程中的代价。非持久连接给服务器带来了沉重的负担,每台服务器可能同时面对数以百计甚至更多的请求。持久连接就是为了解决这些问题,其特点是一直保持TCP连接状态,直到遇到明确的中断要求之后再中断连接。持久连接减少了通信开销,节省了通信量。HTTPSHTTPS介绍HTTP 协议中没有加密机制,但可以通 过和 SSL(Secure Socket Layer, 安全套接层 )或 TLS(Transport Layer Security, 安全层传输协议)的组合使用,加密 HTTP 的通信内容。属于通信加密,即在整个通信线路中加密。HTTP + 加密 + 认证 + 完整性保护 = HTTPS(HTTP Secure )HTTPS 采用共享密钥加密(对称)和公开密钥加密(非对称)两者并用的混合加密机制。若密钥能够实现安全交换,那么有可能会考虑仅使用公开密钥加密来通信。但是公开密钥加密与共享密钥加密相比,其处理速度要慢。所以应充分利用两者各自的优势, 将多种方法组合起来用于通信。 在交换密钥阶段使用公开密钥加密方式,之后的建立通信交换报文阶段 则使用共享密钥加密方式。 HTTPS握手过程的简单描述如下:浏览器将自己支持的一套加密规则发送给网站。服务器获得浏览器公钥。网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。浏览器获得服务器公钥。获得网站证书之后浏览器要做以下工作:证证书的合法性(颁发证书的机构是否合法,证书中包含的网站地址是否与正在访问的地址一致等),如果证书受信任,则浏览器栏里面会显示一个小锁头,否则会给出证书不受信的提示。如果证书受信任,或者是用户接受了不受信的证书,浏览器会生成一串随机数的密码(接下来通信的密钥),并用证书中提供的公钥加密(共享密钥加密)。使用约定好的HASH计算握手消息,并使用生成的随机数对消息进行加密,最后将之前生成的所有信息发送给网站。 浏览器验证 -> 随机密码 服务器的公钥加密 -> 通信的密钥 通信的密钥 -> 服务器网站接收浏览器发来的数据之后要做以下的操作:使用自己的私钥将信息解密取出密码,使用密码解密浏览器发来的握手消息,并验证HASH是否与浏览器发来的一致。使用密码加密一段握手消息,发送给浏览器。服务器用自己的私钥解出随机密码 -> 用密码解密握手消息(共享密钥通信)-> 验证HASH与浏览器是否一致(验证浏览器)HTTPS的不足加密解密过程复杂导致访问速度慢加密需要认向证机构付费整个页面的请求都要使用HTTPSHTTPS的工作原理我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取,所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议。客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤,如图所示。客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。客户端的浏览器与Web服务器开始协商SSL连接的安全等级,也就是信息加密的等级。客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。Web服务器利用自己的私钥解密出会话密钥。Web服务器利用会话密钥加密与客户端之间的通信。HTTP与HTTPS的区别HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。HTTPS和HTTP的区别主要如下:https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。总结相比 HTTP 协议,HTTPS 协议增加了很多握手、加密解密等流程,虽然过程很复杂,但其可以保证数据传输的安全。————————————————版权声明:本文为CSDN博主「Cs 挽周」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/weixin_45692705/article/details/119803588希望对大家有所帮助!
-
MySQL二进制日志截取和恢复 作用数据恢复和主从配置开启二进制日志vim /etc/my.conf [mysqld] server-id=1 #(1~65535) log-bin=/var/lib/mysql/mysql-bin log_bin_index=/var/lib/mysql/mysql-bin.index binlog_format=row sync_binlog=1 //每次事务提交都立即刷写binlog到磁盘 mysql> show variables like '%log_bin%'; +---------------------------------+--------------------------------+ | Variable_name | Value | +---------------------------------+--------------------------------+ | log_bin | ON | | log_bin_basename | /var/lib/mysql/mysql-bin | | log_bin_index | /var/lib/mysql/mysql-bin.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | sql_log_bin | ON | +---------------------------------+--------------------------------+ 6 rows in set (0.00 sec)PS:binlog_format=(row、statement、mixed)statement:SBR,语句模式记录日志,做什么命令,记录什么命令. 可读性较强,对于范围操作日志量少,但是可能会出现记录不准确的情况:insert into xx values (1,'sa',now()). row :RBR,行模式,数据行的变化。可读性较弱,对于范围操作日志大,不会出现记录错误.对高可用环境中的新特性要依赖于RBR(5.7版本默认) mixed :MBR,混合模式查看二进制日志位置:mysql> show variables like '%log_bin%'; # flush logs; 每执行一次就多一个日志 +---------------------------------+--------------------------------+ | Variable_name | Value | +---------------------------------+--------------------------------+ | log_bin | ON | | log_bin_basename | /var/lib/mysql/mysql-bin | | log_bin_index | /var/lib/mysql/mysql-bin.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | sql_log_bin | ON | +---------------------------------+--------------------------------+ 6 rows in set (0.01 sec) mysql> show binary logs; +------------------+-----------+ | Log_name | File_size | +------------------+-----------+ | mysql-bin.000001 | 177 | | mysql-bin.000002 | 154 | +------------------+-----------+ 2 rows in set (0.00 sec) mysql> flush logs; Query OK, 0 rows affected (0.01 sec) mysql> show binary logs; +------------------+-----------+ | Log_name | File_size | +------------------+-----------+ | mysql-bin.000001 | 177 | | mysql-bin.000002 | 201 | | mysql-bin.000003 | 154 | +------------------+-----------+ 3 rows in set (0.00 sec)查看现存的二进制日志show binary logs;查看二进制日志事件show binlog events in 'mysql-bin.000003' limit 5; +------------------+-----+----------------+-----------+-------------+---------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +------------------+-----+----------------+-----------+-------------+---------------------------------------+ | mysql-bin.000003 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.34-log, Binlog ver: 4 | | mysql-bin.000003 | 123 | Previous_gtids | 1 | 154 | | +------------------+-----+----------------+-----------+-------------+---------------------------------------+ 2 rows in set (0.00 sec)在打印出来的信息中可以看到event事件的开始和结束号码,它可以方便我们从日志中截取想要的日志事件查看二进制日志内容[root@cs mysql]# mysqlbinlog mysql-bin.000003 /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; DELIMITER /*!*/; # at 4 #210822 10:27:13 server id 1 end_log_pos 123 CRC32 0x98688dd8 Start: binlog v 4, server v 5.7.34-log created 210822 10:27:13 # Warning: this binlog is either in use or was not closed properly. BINLOG ' AbYhYQ8BAAAAdwAAAHsAAAABAAQANS43LjM0LWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA AdiNaJg= '/*!*/; # at 123 #210822 10:27:13 server id 1 end_log_pos 154 CRC32 0x1ae7a1b6 Previous-GTIDs # [empty] SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/; DELIMITER ; # End of log file /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;查看和分析binlogmysql> show binary logs; mysql> show master status ; mysql> show binlog events in 'binlog.000003'; [root@cs mysql]# mysqlbinlog mysql-bin.000003 [root@cs mysql]# mysqlbinlog --base64-output=decode-rows -vvv mysql-bin.000003模拟数据恢复mysql> flush logs; mysql> create database cs; mysql> use cs; Database changed mysql> create table t1 (id int); Query OK, 0 rows affected (0.05 sec) mysql> insert into t1 values(1); Query OK, 1 row affected (0.01 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> insert into t1 values(2); Query OK, 1 row affected (0.01 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> insert into t1 values(3); Query OK, 1 row affected (0.01 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> drop cs; 开始恢复 mysql> show master status; #当前的二进制文件 +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000004 | 1364 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) mysql> show binlog events in 'mysql-bin.000004'; #查看二进制日志事件(重要的是创建数据库和删除数据库的Pos值) +------------------+------+----------------+-----------+-------------+---------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +------------------+------+----------------+-----------+-------------+---------------------------------------+ | mysql-bin.000004 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.34-log, Binlog ver: 4 | | mysql-bin.000004 | 123 | Previous_gtids | 1 | 154 | | | mysql-bin.000004 | 154 | Anonymous_Gtid | 1 | 219 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 219 | Query | 1 | 307 | create database cs | | mysql-bin.000004 | 307 | Anonymous_Gtid | 1 | 372 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 372 | Query | 1 | 466 | use `cs`; create table t1 (id int) | | mysql-bin.000004 | 466 | Anonymous_Gtid | 1 | 531 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 531 | Query | 1 | 601 | BEGIN | | mysql-bin.000004 | 601 | Table_map | 1 | 644 | table_id: 115 (cs.t1) | | mysql-bin.000004 | 644 | Write_rows | 1 | 684 | table_id: 115 flags: STMT_END_F | | mysql-bin.000004 | 684 | Xid | 1 | 715 | COMMIT /* xid=349 */ | | mysql-bin.000004 | 715 | Anonymous_Gtid | 1 | 780 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 780 | Query | 1 | 850 | BEGIN | | mysql-bin.000004 | 850 | Table_map | 1 | 893 | table_id: 115 (cs.t1) | | mysql-bin.000004 | 893 | Write_rows | 1 | 933 | table_id: 115 flags: STMT_END_F | | mysql-bin.000004 | 933 | Xid | 1 | 964 | COMMIT /* xid=351 */ | | mysql-bin.000004 | 964 | Anonymous_Gtid | 1 | 1029 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 1029 | Query | 1 | 1099 | BEGIN | | mysql-bin.000004 | 1099 | Table_map | 1 | 1142 | table_id: 115 (cs.t1) | | mysql-bin.000004 | 1142 | Write_rows | 1 | 1182 | table_id: 115 flags: STMT_END_F | | mysql-bin.000004 | 1182 | Xid | 1 | 1213 | COMMIT /* xid=353 */ | | mysql-bin.000004 | 1213 | Anonymous_Gtid | 1 | 1278 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' | | mysql-bin.000004 | 1278 | Query | 1 | 1364 | drop database cs | +------------------+------+----------------+-----------+-------------+---------------------------------------+ 23 rows in set (0.00 sec) [root@cs mysql]# mysqlbinlog --start-position=219 --stop-position=1278 /var/lib/mysql/mysql-bin.000004 >/tmp/bin.sql mysql> set sql_log_bin=0; #下面操作不会被记录到二进制文件(慎用) Query OK, 0 rows affected (0.00 sec) mysql> source /tmp/bin.sql; Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.01 sec) Query OK, 0 rows affected (0.00 sec) Charset changed Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected, 1 warning (0.00 sec) Query OK, 1 row affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Database changed Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.02 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.01 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) mysql> set sql_log_bin=1; Query OK, 0 rows affected (0.00 sec) mysql> use cs; Database changed mysql> show tables; +--------------+ | Tables_in_cs | +--------------+ | t1 | +--------------+ 1 row in set (0.00 sec) mysql> select * from t1; +------+ | id | +------+ | 1 | | 2 | | 3 | +------+ 3 rows in set (0.00 sec)
-
MySQL开启慢查询日志 前言数据库日志记录了用户对数据库的各种操作及数据库发生的各种事件。能帮助数据库管理员追踪、分析问题。MySQL提供了错误日志、二进制日志、查询日志、慢查询日志。MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值(long_query_time,单位:秒)的SQL语句。默认情况下,MySQL不启动慢查询日志。本文简单介绍如何开启慢查询日志,如何用mysqldumpslow分析慢查询。参数说明:slow_query_log #慢查询开启状态,ON开启,OFF关闭 slow_query_log_file #慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录) long_query_time #查询超过多少秒才记录 默认10s ,查询命令 SHOW VARIABLES LIKE 'long_query_time'; log_queries_not_using_indexes = 1 #表明记录没有使用索引的 SQL 语句重点说明:开启慢日志版本要高,低版本无法支持,本次版本是: 5.7.34SELECT VERSION(); #查询版本号 或者 show variables like '%version%'配置开启慢查询编辑MySQL配置文件my.cnf在【mysqld】字段下加入:long_query_time=1 #表示记录查询超过1s的sql slow_launch_time=1 #表示如果建立线程花费了比这个值更长的时间,slow_launch_threads 计数器将增加 slow_query_log=ON #开启慢查询日志 slow_query_log_file=/var/lib/mysql/slow_queries.log #慢查询日志记录文件{message type="warning" content="注意:慢查询的日志记录文件对于mysql用户必须可写!!"/}mysql> show variables like 'slow_query%'; +---------------------+---------------------------------+ | Variable_name | Value | +---------------------+---------------------------------+ | slow_query_log | ON | | slow_query_log_file | /var/lib/mysql/slow_queries.log | +---------------------+---------------------------------+ 2 rows in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'long_query_time'; +-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | long_query_time | 1.000000 | +-----------------+----------+ 1 row in set (0.00 sec)测试mysql> select sleep(2); +----------+ | sleep(2) | +----------+ | 0 | +----------+ 1 row in set (2.02 sec)[root@cs ~]# cat /var/lib/mysql/slow_queries.log /usr/sbin/mysqld, Version: 5.7.34-log (MySQL Community Server (GPL)). started with: Tcp port: 0 Unix socket: /var/lib/mysql/mysql.sock Time Id Command Argument # Time: 2021-08-20T10:01:18.841053Z # User@Host: root[root] @ localhost [] Id: 3 # Query_time: 2.023306 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0 SET timestamp=1629453678; select sleep(2);删除慢查询日志慢查询日志的删除方法与通用日志的删除方法是一样的。可以使用 mysqladmin 命令来删除。也可以使用手工方式来删除。mysqladmin 命令的语法如下:mysqladmin -uroot -p flush-logs执行该命令后,命令行会提示输入密码。输入正确密码后,将执行删除操作。新的慢查询日志会直接覆盖旧的查询日志,不需要再手动删除。数据库管理员也可以手工删除慢查询日志,删除之后需要重新启动 MySQL 服务。{message type="warning" content="注意:通用查询日志和慢查询日志都是使用这个命令,使用时一定要注意,一旦执行这个命令,通用查询日志和慢查询日志都只存在新的日志文件中。如果需要备份旧的慢查询日志文件,必须先将旧的日志改名,然后重启 MySQL 服务或执行 mysqladmin 命令。"/}
-